The Effects of CPU Turbo: 768X stddev
I build and maintain smf - the fastest RPC in the west. The main language supported is C++. We use Seastar as the actual asynchronous framework.
The RPC protocol uses flatbuffers to make cross language support possible, in addition to
its main goal of providing zero cost deserialization on the receiving side.
Currently, Go and Java are in the process of being added to the repo,
with partial support already merged.
On Friday, June 28 2018, I got a text from a friend
that said: last time I checked flatbuffers was slow vs cap 'n proto.
At first, I was suspicious, since I’ve never seen flatbuffers be
in any top $> perf profile of any kind, on real production applications. However,
I had no numbers or benchmarks to prove it.
I thought I had a quick-and-dirty hack to amortize the cost of object graphs - it never occurred to me to measure large type trees or large buffers.
BLUF - Bottom Line Up Front.
I had introduced a performance optimization that actually turned out to be bad for large buffers.
To be precise:
- On small very buffers it was ~6% faster
- On large buffers it was ~41% slower
nooooooooooooooooooooooooooo!
The beginning of yak-shaving
I found a project that had benchmarked
cap'n proto vs flatbuffers. In particular, it measures buffer construction,
since both cap’n proto and flatbuffers deserialization is effectively a pointer cast - Yay
for little endian enforced encoding into an aligned byte array.
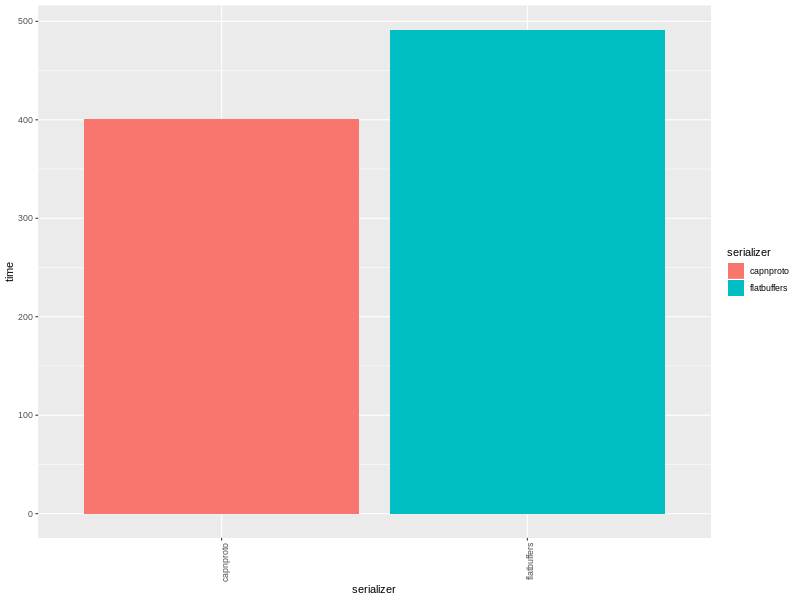
The cpp-serializers project measures cap’n proto vs flatbuffers encoding and to my surprise, flatbuffers measured at 2.5X slower.
auto start = std::chrono::high_resolution_clock::now();
for (size_t i = 0; i < iterations; i++) {
flatbuffers::FlatBufferBuilder builder;
strings.clear();
for (size_t i = 0; i < kStringsCount; i++) {
strings.push_back(builder.CreateString(kStringValue));
}
auto ids_vec = builder.CreateVector(kIntegers);
auto strings_vec = builder.CreateVector(strings);
auto r1 = CreateRecord(builder, ids_vec, strings_vec);
builder.Finish(r1);
auto p = reinterpret_cast<char*>(builder.GetBufferPointer());
auto sz = builder.GetSize();
std::vector<char> buf(p, p + sz);
auto r2 = GetRecord(buf.data());
(void)r2->ids()[0];
builder.ReleaseBufferPointer();
}
auto finish = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(finish - start).count();As you can see, the benchmark creates a flatbuffers builder (a kind of std::vector). It stresses
the builder by allocating an array of strings and ints… and that’s about it.
Internally, the flatbuffers::FlatbufferBuilder encodes from top-to-bottom (downward growth) and when
it reaches the bottom, it reallocs and grows the size of the underlying array to fit the contents.
The actual code for reallocation is:
void reallocate(size_t len) {
FLATBUFFERS_ASSERT(allocator_);
auto old_reserved = reserved_;
auto old_size = size();
auto old_scratch_size = scratch_size();
reserved_ += (std::max)(len,
old_reserved ? old_reserved / 2 : initial_size_);
reserved_ = (reserved_ + buffer_minalign_ - 1) & ~(buffer_minalign_ - 1);
if (buf_) {
buf_ = allocator_->reallocate_downward(buf_, old_reserved, reserved_,
old_size, old_scratch_size);
} else {
buf_ = allocator_->allocate(reserved_);
}
cur_ = buf_ + reserved_ - old_size;
scratch_ = buf_ + old_scratch_size;
}It grows by powers of 2 (reserved_ + buffer_minalign_ - 1) & ~(buffer_minalign_ - 1);
, and usually by 1024 bytes which is the default initial_size_;
Setup
Let’s start with a Flatbuffers IDL of a simple key=value struct.
table kvpair {
key: string;
value: string;
}The C++ API has a nice object api on top of the raw flatbuffers::FlatbufferBuilder, so
a quick GoogleBenchmark yields something like this:
static inline kvpairT
gen_kv(uint32_t sz) {
kvpairT ret;
ret.key.resize(sz, 'x');
ret.value.resize(sz, 'y');
return ret;
}
static void
BM_alloc_simple(benchmark::State &state) {
for (auto _ : state) {
state.PauseTiming();
auto kv = gen_kv(state.range(0));
state.ResumeTiming();
// build it!
flatbuffers::FlatBufferBuilder bdr;
bdr.Finish(kvpair::Pack(bdr, &kv, nullptr));
auto mem = bdr.Release();
auto ptr = reinterpret_cast<char *>(mem.data());
auto sz = mem.size();
auto buf = seastar::temporary_buffer<char>(
ptr, sz, seastar::make_object_deleter(std::move(mem)));
benchmark::DoNotOptimize(buf);
}
}
BENCHMARK(BM_alloc_simple)
->Args({1 << 1, 1 << 1})
->Args({1 << 2, 1 << 2})
->Args({1 << 4, 1 << 4})
->Args({1 << 8, 1 << 8})
->Args({1 << 12, 1 << 12})
->Args({1 << 16, 1 << 16})
->Args({1 << 18, 1 << 18});A few things to note:
- We use
auto mem = bdr.Release();and wrap that into aseastar::temporary_buffer<char>with effectively zero copy (+- some pointer assignments). - This is important because our entire messaging API is about bridging the code generation from flatbuffers and seastar.
- In addition to this, our RPC mechanism codegen’s seastar <–> flatbuffers glue code.
---------------------------------------------------------------------------
Benchmark Time CPU Iterations
---------------------------------------------------------------------------
...
BM_alloc_simple/2/2/threads:1 586 ns 588 ns 1184218
BM_alloc_simple/4/4/threads:1 586 ns 589 ns 1181340
BM_alloc_simple/16/16/threads:1 598 ns 600 ns 1153577
BM_alloc_simple/256/256/threads:1 601 ns 602 ns 1147963
BM_alloc_simple/4096/4096/threads:1 824 ns 828 ns 837036
BM_alloc_simple/65536/65536/threads:1 6825 ns 6845 ns 101321
...
To encode a 2 x 64KB buffers it takes 6.8 micros. Yikes! - But is this bad?
(as of flatbuffers checkin 34cb163e389e928db08ed2bd0e16ee0ac53ab1ce).
Note this is only 3X the cost of std::malloc + std::memset, which is the fastest
thing I can think of as a base comparison.
Before we dive into possible optimizations, let’s fix our desktop for these micro optimizations.
Fixing the environment
function cpu_disable_performance_cpupower_state(){
sudo cpupower frequency-set --governor powersave
}
function cpu_enable_performance_cpupower_state(){
sudo cpupower frequency-set --governor performance
}
function cpu_available_frequencies() {
for i in /sys/devices/system/cpu/cpu[0-9]*; do
echo "$i:"
echo "$i/cpufreq/scaling_min_freq: $(cat $i/cpufreq/scaling_min_freq)";
echo "$i/cpufreq/scaling_max_freq: $(cat $i/cpufreq/scaling_max_freq)";
done
}
function cpu_set_min_frequencies() {
local freq=$1;
if [[ $freq == "" ]]; then exit 1; fi
for i in /sys/devices/system/cpu/cpu[0-9]*; do
echo "$i:"
echo "$i/cpufreq/scaling_min_freq: $(cat $i/cpufreq/scaling_min_freq)";
echo "$freq" | sudo tee "$i/cpufreq/scaling_min_freq"
echo "$i/cpufreq/scaling_min_freq: $(cat $i/cpufreq/scaling_min_freq)";
done
}
function cpu_set_max_frequencies() {
local freq=$1;
if [[ $freq == "" ]]; then exit 1; fi
for i in /sys/devices/system/cpu/cpu[0-9]*; do
echo "$i:"
echo "$i/cpufreq/scaling_max_freq: $(cat $i/cpufreq/scaling_max_freq)";
echo "$freq" | sudo tee "$i/cpufreq/scaling_max_freq"
echo "$i/cpufreq/scaling_max_freq: $(cat $i/cpufreq/scaling_max_freq)";
done
}My CPU is a Intel(R) Xeon(R) CPU E3-1535M v6 @ 3.10GHz with a turbo of 4.20GHz. That’s great for desktop experience where interactivity matters and terrible for performance benchmarking.
When I first tried to show the results to my partner (non CS Major, but puts up w/ me asking her to stare at my screen) I had unpredictable results.
Armed w/ the shell funcs above, my checklist is now as follows:
Settings
- Ensure that your BIOS says performance when connected to AC
- Check your CPU freqencies via
cat /proc/cpuinfo | grep model - Set your CPU governor via
cpu_enable_performance_cpupower_state - Set the min frequency to the frequency reported by your CPU/model/vendor via:
cpu_set_min_frequencies 3100000in my case - Set the max frequency to the frequency reported by your CPU/model/vendor via:
cpu_set_max_frequencies 3100000in my case - Verify that you always build in Release mode
Verying the frequencies is now simple via cpu_available_frequencies
$> cpu_available_frequencies
/sys/devices/system/cpu/cpu0:
/sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq: 3100000
/sys/devices/system/cpu/cpu0/cpufreq/scaling_max_freq: 3100000
/sys/devices/system/cpu/cpu1:
/sys/devices/system/cpu/cpu1/cpufreq/scaling_min_freq: 3100000
/sys/devices/system/cpu/cpu1/cpufreq/scaling_max_freq: 3100000
/sys/devices/system/cpu/cpu2:
/sys/devices/system/cpu/cpu2/cpufreq/scaling_min_freq: 3100000
/sys/devices/system/cpu/cpu2/cpufreq/scaling_max_freq: 3100000
/sys/devices/system/cpu/cpu3:
/sys/devices/system/cpu/cpu3/cpufreq/scaling_min_freq: 3100000
/sys/devices/system/cpu/cpu3/cpufreq/scaling_max_freq: 3100000
/sys/devices/system/cpu/cpu4:
/sys/devices/system/cpu/cpu4/cpufreq/scaling_min_freq: 3100000
/sys/devices/system/cpu/cpu4/cpufreq/scaling_max_freq: 3100000
/sys/devices/system/cpu/cpu5:
/sys/devices/system/cpu/cpu5/cpufreq/scaling_min_freq: 3100000
/sys/devices/system/cpu/cpu5/cpufreq/scaling_max_freq: 3100000
/sys/devices/system/cpu/cpu6:
/sys/devices/system/cpu/cpu6/cpufreq/scaling_min_freq: 3100000
/sys/devices/system/cpu/cpu6/cpufreq/scaling_max_freq: 3100000
/sys/devices/system/cpu/cpu7:
/sys/devices/system/cpu/cpu7/cpufreq/scaling_min_freq: 3100000
/sys/devices/system/cpu/cpu7/cpufreq/scaling_max_freq: 3100000The take away is you don’t necessarily want speed, you want predictability.
Next - Compiler Explorer - my new fav tool
First, let’s execute the commands above and get the compiler flags that we’ll need for compiler explorer.
If you are using CMake, follow these screencasts and don’t forget to set
set(CMAKE_EXPORT_COMPILE_COMMANDS 1) on your main CMakeLists.txt file
Now that we have the compiler flags ready, let’s fire up compiler explorer:
When you navigate to localhost:1024 you are welcomed with the usual and friendly CompilerExplorer UI.
With these tools we can now benchmark & optimize our code
The results
Running /home/agallego/workspace/smf/build/release/src/benchmarks/fbs_alloc/smf_fbsalloc_benchmark_test
Run on (8 X 4200 MHz CPU s)
CPU Caches:
L1 Data 32K (x4)
L1 Instruction 32K (x4)
L2 Unified 256K (x4)
L3 Unified 8192K (x1)
---------------------------------------------------------------------------
Benchmark Time CPU Iterations
---------------------------------------------------------------------------
BM_malloc_base/2/2/threads:1 11 ns 11 ns 62858390
BM_malloc_base/4/4/threads:1 11 ns 11 ns 61565906
BM_malloc_base/16/16/threads:1 11 ns 11 ns 64118519
BM_malloc_base/256/256/threads:1 20 ns 20 ns 35574778
BM_malloc_base/4096/4096/threads:1 98 ns 98 ns 7123958
BM_malloc_base/65536/65536/threads:1 2339 ns 2336 ns 281254
BM_malloc_base/262144/262144/threads:1 11648 ns 11635 ns 58503
BM_alloc_simple/2/2/threads:1 586 ns 588 ns 1184218
BM_alloc_simple/4/4/threads:1 586 ns 589 ns 1181340
BM_alloc_simple/16/16/threads:1 598 ns 600 ns 1153577
BM_alloc_simple/256/256/threads:1 601 ns 602 ns 1147963
BM_alloc_simple/4096/4096/threads:1 824 ns 828 ns 837036
BM_alloc_simple/65536/65536/threads:1 6825 ns 6845 ns 101321
BM_alloc_simple/262144/262144/threads:1 32838 ns 32784 ns 21351
BM_alloc_thread_local/2/2/threads:1 557 ns 559 ns 1220122
BM_alloc_thread_local/4/4/threads:1 557 ns 559 ns 1221065
BM_alloc_thread_local/16/16/threads:1 569 ns 571 ns 1198623
BM_alloc_thread_local/256/256/threads:1 578 ns 580 ns 1181208
BM_alloc_thread_local/4096/4096/threads:1 806 ns 819 ns 845698
BM_alloc_thread_local/65536/65536/threads:1 10182 ns 10237 ns 68206
BM_alloc_thread_local/262144/262144/threads:1 43066 ns 42998 ns 16279
BM_alloc_hybrid/2/2/threads:1 563 ns 565 ns 1212235
BM_alloc_hybrid/4/4/threads:1 563 ns 566 ns 1209207
BM_alloc_hybrid/16/16/threads:1 577 ns 579 ns 1185042
BM_alloc_hybrid/256/256/threads:1 587 ns 589 ns 1166182
BM_alloc_hybrid/4096/4096/threads:1 843 ns 847 ns 819194
BM_alloc_hybrid/65536/65536/threads:1 6810 ns 6832 ns 101497
BM_alloc_hybrid/262144/262144/threads:1 32838 ns 32774 ns 21368As expected, for small buffers, there is a large cost vs the base of malloc+memset, and at the higher ends, the allocation & byte traversal start to dominate. The range is ~58x (worst) - ~2.8X (best).
Our benched code
#include <cstring>
#include <memory>
#include <thread>
#include <benchmark/benchmark.h>
#include <core/print.hh>
#include <core/sstring.hh>
#include <core/temporary_buffer.hh>
#include "kv_generated.h"
#include "smf/native_type_utils.h"
static inline kvpairT
gen_kv(uint32_t sz) {
kvpairT ret;
ret.key.resize(sz, 'x');
ret.value.resize(sz, 'y');
return ret;
}
static void
BM_malloc_base(benchmark::State &state) {
for (auto _ : state) {
auto buf = reinterpret_cast<char *>(std::malloc(2 * state.range(0)));
std::memset(buf, 'x', 2 * state.range(0));
benchmark::DoNotOptimize(buf);
std::free(buf);
}
}
BENCHMARK(BM_malloc_base)
->Args({1 << 1, 1 << 1})
->Args({1 << 2, 1 << 2})
->Args({1 << 4, 1 << 4})
->Args({1 << 8, 1 << 8})
->Args({1 << 12, 1 << 12})
->Args({1 << 16, 1 << 16})
->Args({1 << 18, 1 << 18})
->Threads(1);
static void
BM_alloc_simple(benchmark::State &state) {
for (auto _ : state) {
state.PauseTiming();
auto kv = gen_kv(state.range(0));
state.ResumeTiming();
// build it!
flatbuffers::FlatBufferBuilder bdr;
bdr.Finish(kvpair::Pack(bdr, &kv, nullptr));
auto mem = bdr.Release();
auto ptr = reinterpret_cast<char *>(mem.data());
auto sz = mem.size();
auto buf = seastar::temporary_buffer<char>(
ptr, sz, seastar::make_object_deleter(std::move(mem)));
benchmark::DoNotOptimize(buf);
}
}
BENCHMARK(BM_alloc_simple)
->Args({1 << 1, 1 << 1})
->Args({1 << 2, 1 << 2})
->Args({1 << 4, 1 << 4})
->Args({1 << 8, 1 << 8})
->Args({1 << 12, 1 << 12})
->Args({1 << 16, 1 << 16})
->Args({1 << 18, 1 << 18})
->Threads(1);
static void
BM_alloc_thread_local(benchmark::State &state) {
static thread_local flatbuffers::FlatBufferBuilder bdr(1024);
for (auto _ : state) {
state.PauseTiming();
auto kv = gen_kv(state.range(0));
state.ResumeTiming();
// key operations
bdr.Clear();
bdr.Finish(kvpair::Pack(bdr, &kv, nullptr));
// ned key operations
// std::cout << "Size to copy: " << bdr.GetSize() << std::endl;
void *ret = nullptr;
auto r = posix_memalign(&ret, 8, bdr.GetSize());
if (r == ENOMEM) {
throw std::bad_alloc();
} else if (r == EINVAL) {
throw std::runtime_error(seastar::sprint(
"Invalid alignment of %d; allocating %d bytes", 8, bdr.GetSize()));
}
DLOG_THROW_IF(r != 0,
"ERRNO: {}, Bad aligned allocation of {} with alignment: {}", r,
bdr.GetSize(), 8);
std::memcpy(ret, reinterpret_cast<const char *>(bdr.GetBufferPointer()),
bdr.GetSize());
benchmark::DoNotOptimize(ret);
std::free(ret);
}
}
BENCHMARK(BM_alloc_thread_local)
->Args({1 << 1, 1 << 1})
->Args({1 << 2, 1 << 2})
->Args({1 << 4, 1 << 4})
->Args({1 << 8, 1 << 8})
->Args({1 << 12, 1 << 12})
->Args({1 << 16, 1 << 16})
->Args({1 << 18, 1 << 18})
->Threads(1);
template <typename RootType>
seastar::temporary_buffer<char>
hybrid(const typename RootType::NativeTableType &t) {
static thread_local auto builder =
std::make_unique<flatbuffers::FlatBufferBuilder>();
auto &bdr = *builder.get();
bdr.Clear();
bdr.Finish(RootType::Pack(bdr, &t, nullptr));
if (SMF_UNLIKELY(bdr.GetSize() > 2048)) {
auto mem = bdr.Release();
auto ptr = reinterpret_cast<char *>(mem.data());
auto sz = mem.size();
// fix the original builder
builder = std::make_unique<flatbuffers::FlatBufferBuilder>();
return seastar::temporary_buffer<char>(
ptr, sz, seastar::make_object_deleter(std::move(mem)));
}
// always allocate to the largest member 8-bytes
void *ret = nullptr;
auto r = posix_memalign(&ret, 8, bdr.GetSize());
if (r == ENOMEM) {
throw std::bad_alloc();
} else if (r == EINVAL) {
throw std::runtime_error(seastar::sprint(
"Invalid alignment of %d; allocating %d bytes", 8, bdr.GetSize()));
}
DLOG_THROW_IF(r != 0,
"ERRNO: {}, Bad aligned allocation of {} with alignment: {}", r,
bdr.GetSize(), 8);
seastar::temporary_buffer<char> retval(reinterpret_cast<char *>(ret),
bdr.GetSize(), seastar::make_free_deleter(ret));
std::memcpy(retval.get_write(),
reinterpret_cast<const char *>(bdr.GetBufferPointer()), retval.size());
return std::move(retval);
}
static void
BM_alloc_hybrid(benchmark::State &state) {
for (auto _ : state) {
state.PauseTiming();
auto kv = gen_kv(state.range(0));
state.ResumeTiming();
auto buf = hybrid<kvpair>(kv);
benchmark::DoNotOptimize(buf);
}
}
BENCHMARK(BM_alloc_hybrid)
->Args({1 << 1, 1 << 1})
->Args({1 << 2, 1 << 2})
->Args({1 << 4, 1 << 4})
->Args({1 << 8, 1 << 8})
->Args({1 << 12, 1 << 12})
->Args({1 << 16, 1 << 16})
->Args({1 << 18, 1 << 18})
->Threads(1);
BENCHMARK_MAIN();Lessons Learned: Benchmarking with turbo is dishonest.
Not that people writing OSS (or any software really) are out there to get you. It is just easy to forget to tune your machine specifically for benchmarking. There is no such thing as a quick and dirty benchmark especially if the results are not categorically different, i.e.: 1 minute vs 10 mins vs 1hr.
Let’s compare the stability of multiple runs with turbo vs without.
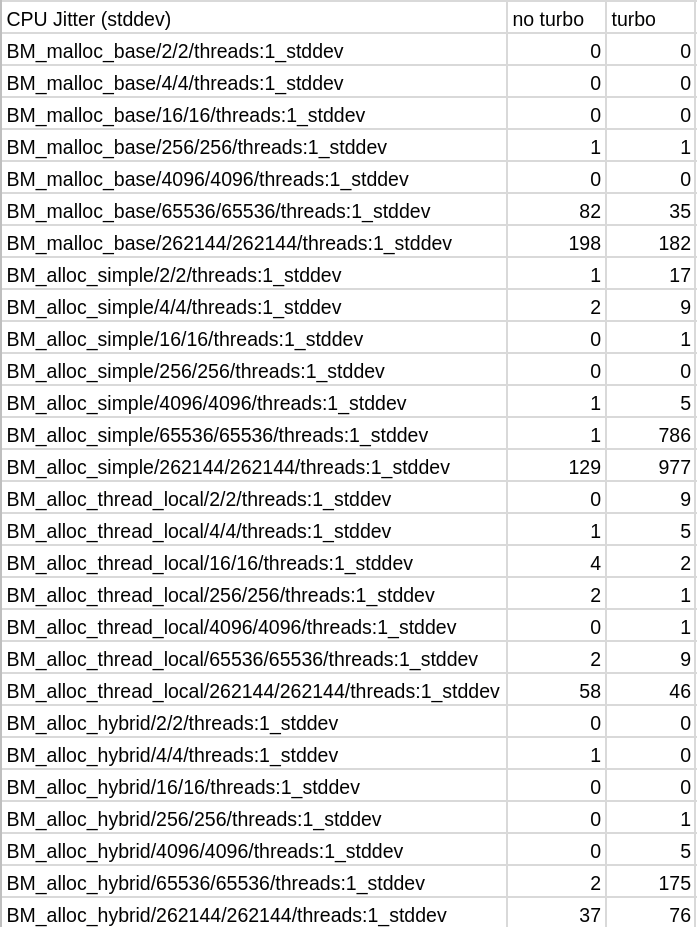
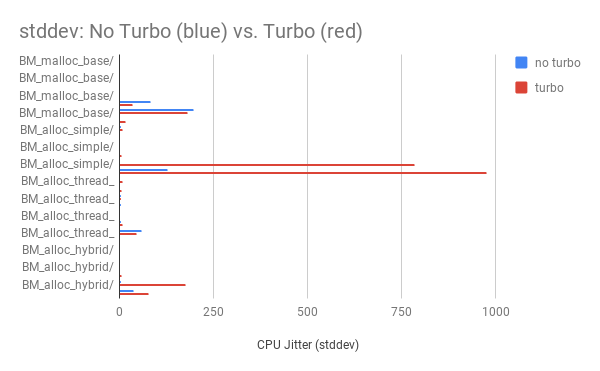
That’s a stddev difference of up to 768X !!!
No-turbo means precisely this:
cpu_available_frequencies
/sys/devices/system/cpu/cpu0:
/sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq: 800000
/sys/devices/system/cpu/cpu0/cpufreq/scaling_max_freq: 4200000
/sys/devices/system/cpu/cpu1:
/sys/devices/system/cpu/cpu1/cpufreq/scaling_min_freq: 800000
/sys/devices/system/cpu/cpu1/cpufreq/scaling_max_freq: 4200000
/sys/devices/system/cpu/cpu2:
/sys/devices/system/cpu/cpu2/cpufreq/scaling_min_freq: 800000
/sys/devices/system/cpu/cpu2/cpufreq/scaling_max_freq: 4200000
/sys/devices/system/cpu/cpu3:
/sys/devices/system/cpu/cpu3/cpufreq/scaling_min_freq: 800000
/sys/devices/system/cpu/cpu3/cpufreq/scaling_max_freq: 4200000
/sys/devices/system/cpu/cpu4:
/sys/devices/system/cpu/cpu4/cpufreq/scaling_min_freq: 800000
/sys/devices/system/cpu/cpu4/cpufreq/scaling_max_freq: 4200000
/sys/devices/system/cpu/cpu5:
/sys/devices/system/cpu/cpu5/cpufreq/scaling_min_freq: 800000
/sys/devices/system/cpu/cpu5/cpufreq/scaling_max_freq: 4200000
/sys/devices/system/cpu/cpu6:
/sys/devices/system/cpu/cpu6/cpufreq/scaling_min_freq: 800000
/sys/devices/system/cpu/cpu6/cpufreq/scaling_max_freq: 4200000
/sys/devices/system/cpu/cpu7:
/sys/devices/system/cpu/cpu7/cpufreq/scaling_min_freq: 800000
/sys/devices/system/cpu/cpu7/cpufreq/scaling_max_freq: 4200000SMF
smf just got 40% faster for large buffers thanks to these benchmarks, if you give it a shot let me know. Stay tuned for the Java and Go code generators and performance benchmarks coming soon.
Let me know if you found this useful, any missinformation, or additional performance tunning on twitter @emaxerrno.
Special thanks to my partner Sarah Rohrbach as well as Chris Heller, Noah Watkins for reading earlier drafts of this post.