A tale of performance debugging: from 1.3X slower to 48X faster than Apache Kafka
I recently wrote a
log file writer
that allows for multiple non-sequential writes to an
O_DIRECT file handle on XFS. Specifically, it dispatches 4 (configurable)
concurrent writes, then does a join of the page-aligned buffer
writes. That file writer handles timed-based flushing policy,
so that you can have a reasonable idea of when your data actually makes it
to disk by either exceeding capacity (say 1MB), or exceeding a timeout
(say 1second).
All of this work, was to design a ( very? ) fast Write Ahead Log (the astute reader will be quick to point out that if you don’t flush at every write, is not really a WAL, but just a log writer). After all of this work (~2K LOC), my heart was broken to realize I was actually -1.3X slower than Apache Kafka after the big re-write! sigh… (tested with the non DPDK runtime - for those of you who have been following along).
For the impatient, what follows is the performance debugging process to understand my bottlenecks, and slowly bring performance to a new high of 48X times faster than Apache Kafka, which was my baseline.
1) I used Apache Kafka tail latency as a my largest latency budget.
2) These tests did not use the DPDK runtime. Only epoll + new aio
Max latency budget: Kafka on NVMe + XFS + kernel 4.14.16-300.fc27.x86_64
To have a useful baseline for my largest latency budget, I enabled lz4 compression for Kafka (much slower w/out it), and also increase the number of partitions to 32. This is the same number of partitions that our broker used for the tests.
# config/server.properties
compression.codec=3
num.partitions=32I was using the latest 1.0 release: kafka_2.11-1.0.0.
# produce 100MM records
#
#
time ./bin/kafka-run-class.sh \
org.apache.kafka.tools.ProducerPerformance \
--topic test \
--num-records 100000000 \
--record-size 100 \
--throughput -1 \
--producer-props acks=1 bootstrap.servers=localhost:9092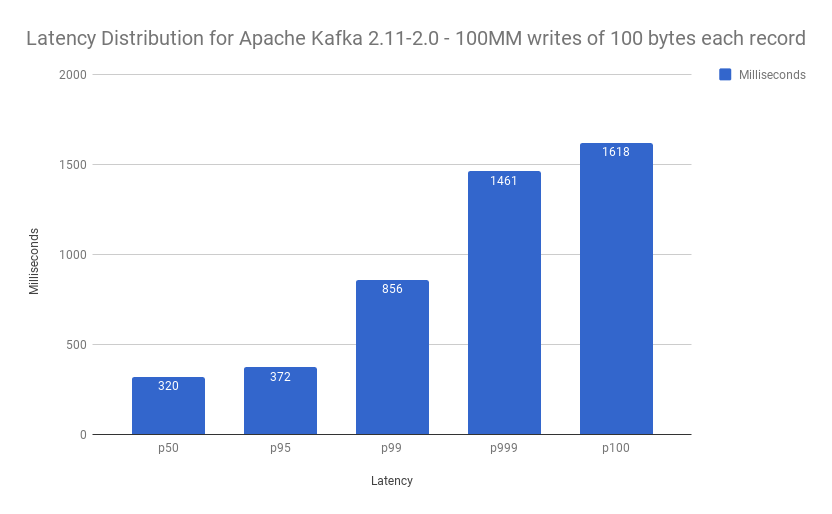
|
Acknowledgements:
1) I disabled all other apps, browsers, etc.
2) localhost has in-kernel optimizations which will only add latency on a prod deployment which will likely go through a network rack
3) This ignores CPU scaling (power states) among others
perf {stat,record,list} & toplev (PMU_tools)
When in doubt, measure. When 100% sure, still measure. 90% of the improvements actually came from an area I wasn’t expecting. 10% did come from a code path I intuited needed some TLC.
In fact, to be 100% honest, I am still in awe at the results. In part the starting profile and ending profile look superficially similar, as you will soon see. In part because this was the first time I was using hardware counters to actually debug a program and realized that I would not have missed out on some sleep had I learned this earlier in life.
My weight-loss-program is as follows:
- perf record -g -p
<pid> - perf report
- If something non-obvious wasn’t there, then:
- perf stat -d -p
<pid> - perf record -g -p
<pid> - perf report
- CPU Flamegraph
- toplev.py
- perf stat -d -p
1st non-obvious performance bottleneck std::sort
diff --git a/src/filesystem/wal_write_behind_cache.cc b/src/filesystem/wal_write_behind_cache.cc
index a35f8ccd..dab6711f 100644
--- a/src/filesystem/wal_write_behind_cache.cc
+++ b/src/filesystem/wal_write_behind_cache.cc
@@ -68,8 +68,6 @@ wal_write_behind_cache::put(uint64_t offset, item_ptr data) {
stats_.bytes_written += data->on_disk_size();
puts_.emplace(offset, data);
keys_.push_back(offset);
- // keeping order is hugely important for removing data.
- std::sort(keys_.begin(), keys_.end());
}
If you decide to repro at home, please comment wal_write_ahead_log.cc:57 and wal_write_ahead_log.cc:23
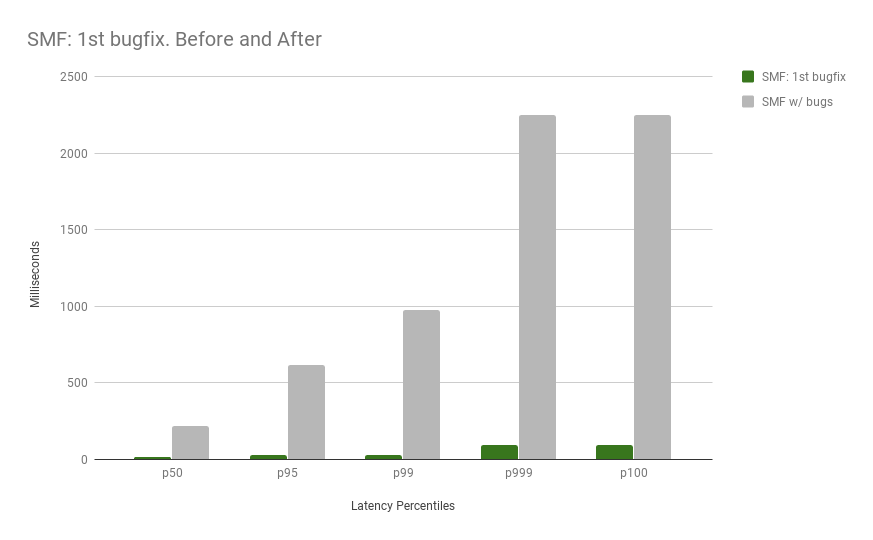
This is a very slow commit. This is when I found out I needed to do something about it immediately. Look at these numbers! yikes.
|
….this is 24x improvement!!! - One line of code.
Finding the culprit!
Going back to our weight-loss program:
# assume 24776 is the process id
#
perf record -F 99 -g -p 24776
# run the client test then call:
#
perf report
|

|
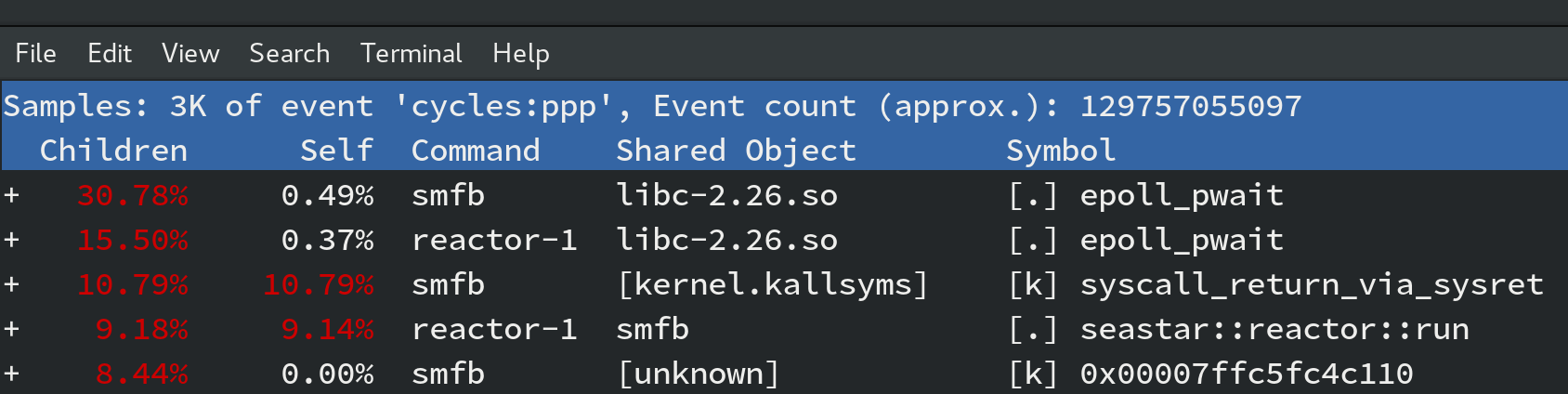
… woah! 74% of the time is spent sorting uint64_t
|
… Yay!! no more bottleneck… but wait! Doesn’t this change break correctness? - No, this was a leftover code from a previous imlementation and honestly, pretty harmless for the behavior of the program other than it made it unbearably slow!
2nd improvement: poor data locality - code slaying
Remember our recipe from above? The perf report no longer shows
something obvious! … what to do!!??!
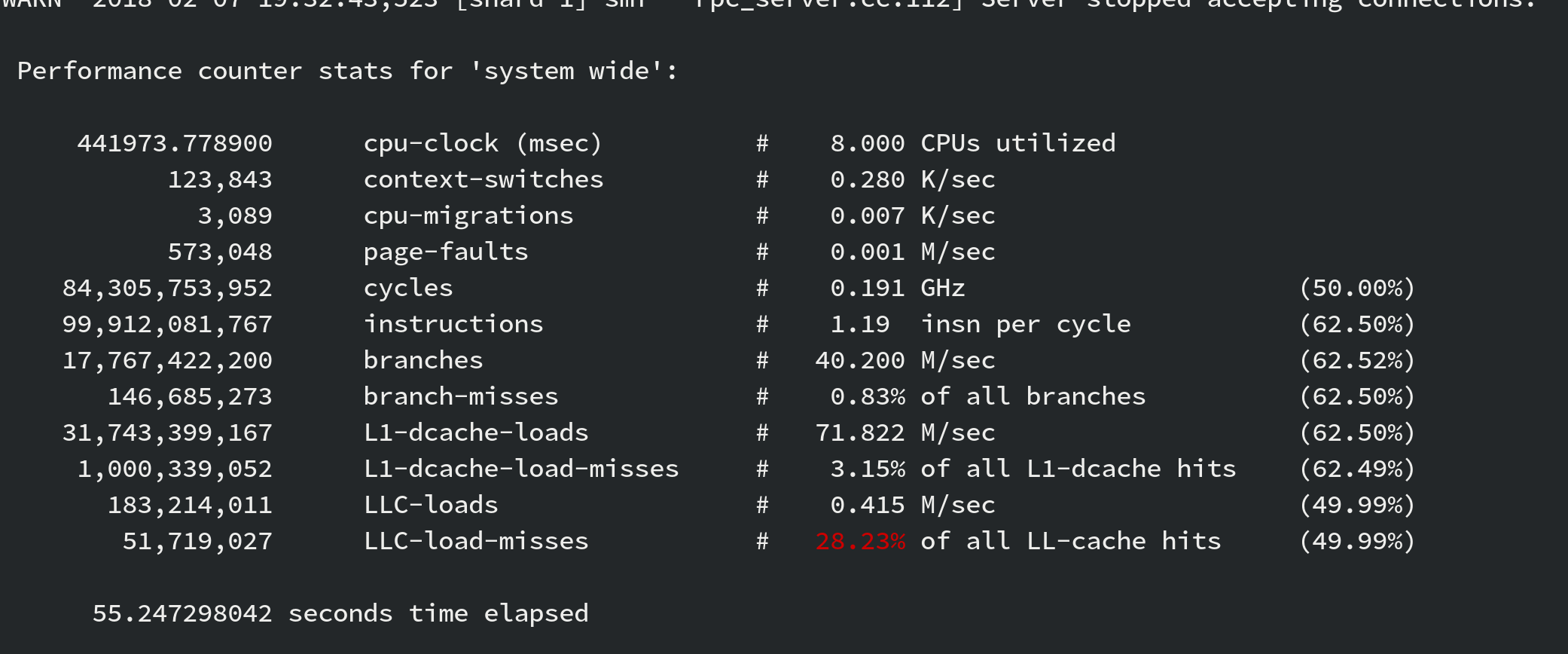
perf stat -d -p <pid> to the rescue!
|
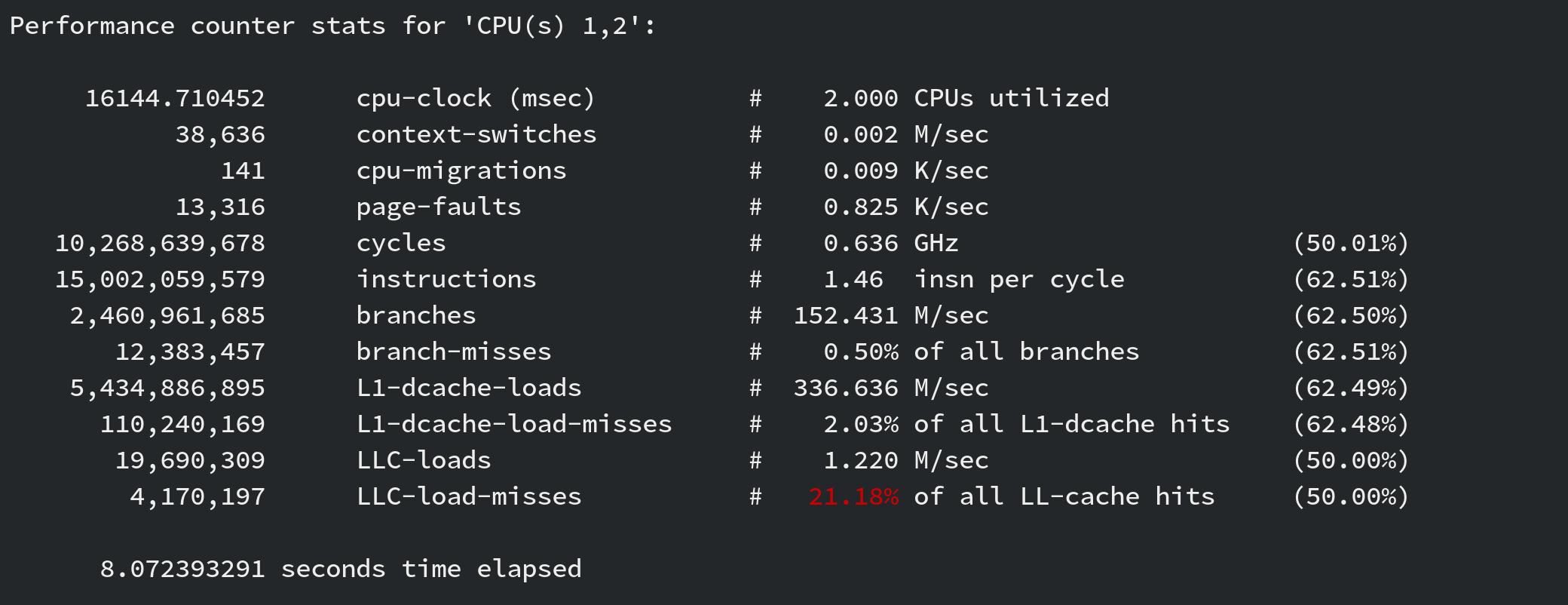
The issue is then… what does this actually mean! LLC stands for last level cache, which in turn it means you are fetching from main memory. … a lot.
This is the first time I’ve used this tool, and instead of doing
a perf record -e LLC-cache-misses I decided to fix it.
I went ahead and said - oh I know better - it’s basically a bunch of
pointer chasing (correct), let me fix it right here…(incorrect)
|
Changing code from pointers to stack allocated structures did have an improvement on the LLC-cache-misses but, not nearly enough. I ended up ‘fixing’ non broken code because I thought I knew better than my profiler.
3rd improvement: poor data locality - non intuitive fix 2
perf record \
-e LLC-loads,LLC-load-misses,instructions \
-e cycles,branch-load-misses,faults \
-e bus-cycles,mem-loads,mem-stores -a -p <pid> |
 |
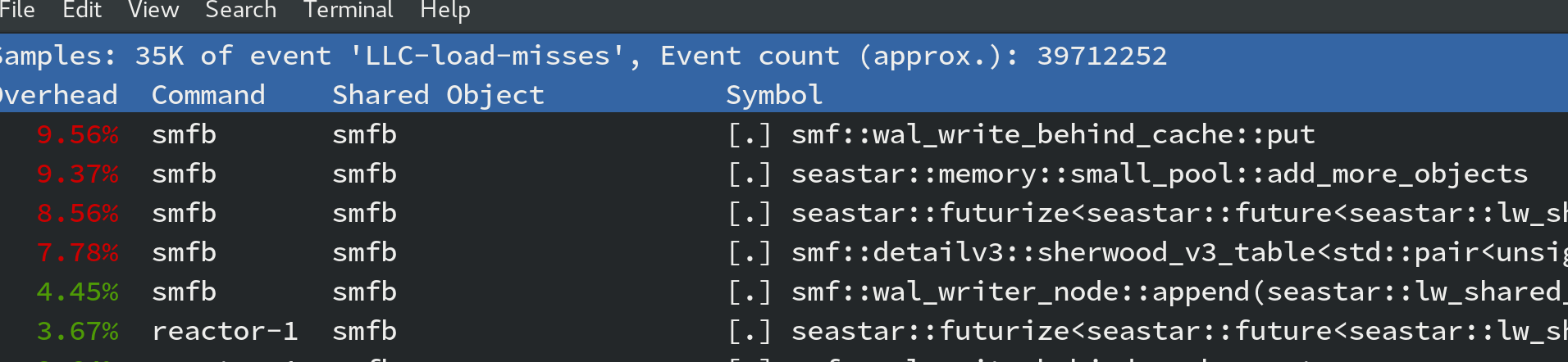 |
It took a long time to play with the annotated perf report and
reading the assembly and the culprits for the LLC-cache-misses, but the
biggest contributor was to move fron an indexed datastructure to a simple array.
Effectively the map was already pre-ordered as writes happen
monotonically. Switching algorithms from a map.find() to std::lower_bound
with a std::deque<> was the biggest contributor.
 |
The second contributor was to actually to cache the size of the
item in wrapper datastructure. That is, I moved from
key.ptr->get_size_on_disk() to a strcut that remembered the size_on_disk
such that you could simply do
key.size_on_disk. That was cached upon insertion into the cache.
This was the the most mind blowing part of this whole thing that in retrospect makes total sense. Jumping around memory (insert refs) is slow and causes CPU stalls if the access patterns are pseudo-random and the CPU prefetcher cannot help you.
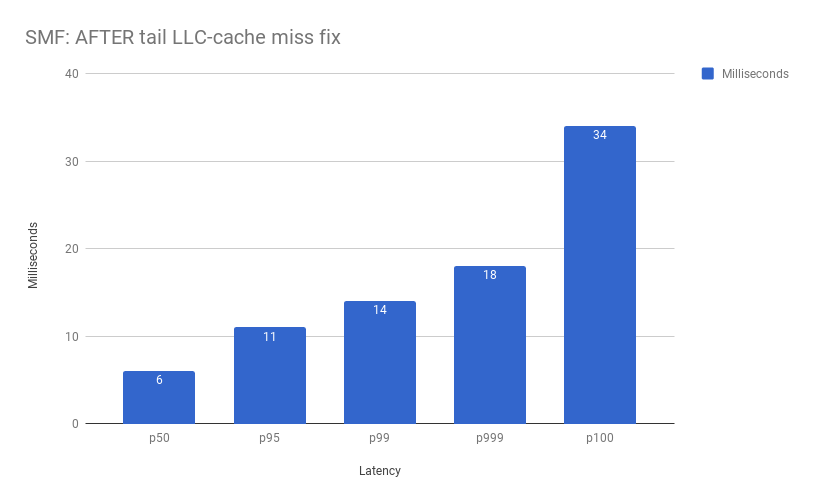 |
Results
At this stage you can tell:
Kafka.Slowest(1618ms) / SMF.Slowest(34ms) ~= 48 lower latency
# CLIENT: inside smf/build_release
#
#
./src/smfb/client/smfb_low_level_client \
--req-num=12202 \
--batch-size=8196 \
--cpuset 3,4 \
--key=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \
--value=yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy \
--poll-mode# SERVER: inside smf/build_release
#
#
../src/smfb/smfb --poll-aio=1 \
--write-ahead-log-dir=. \
--cpuset 1,2 \
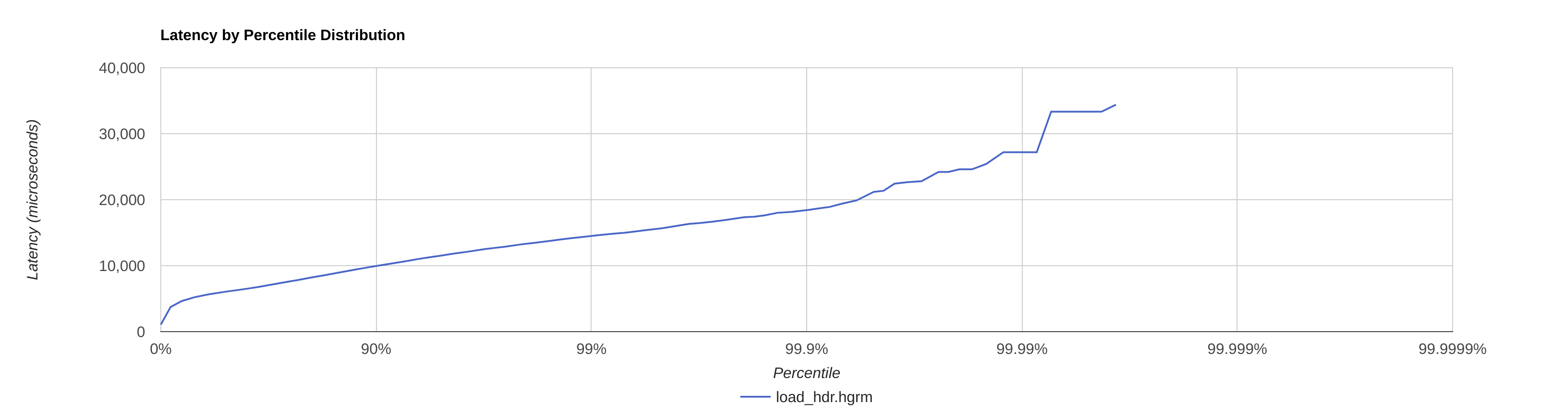
--poll-mode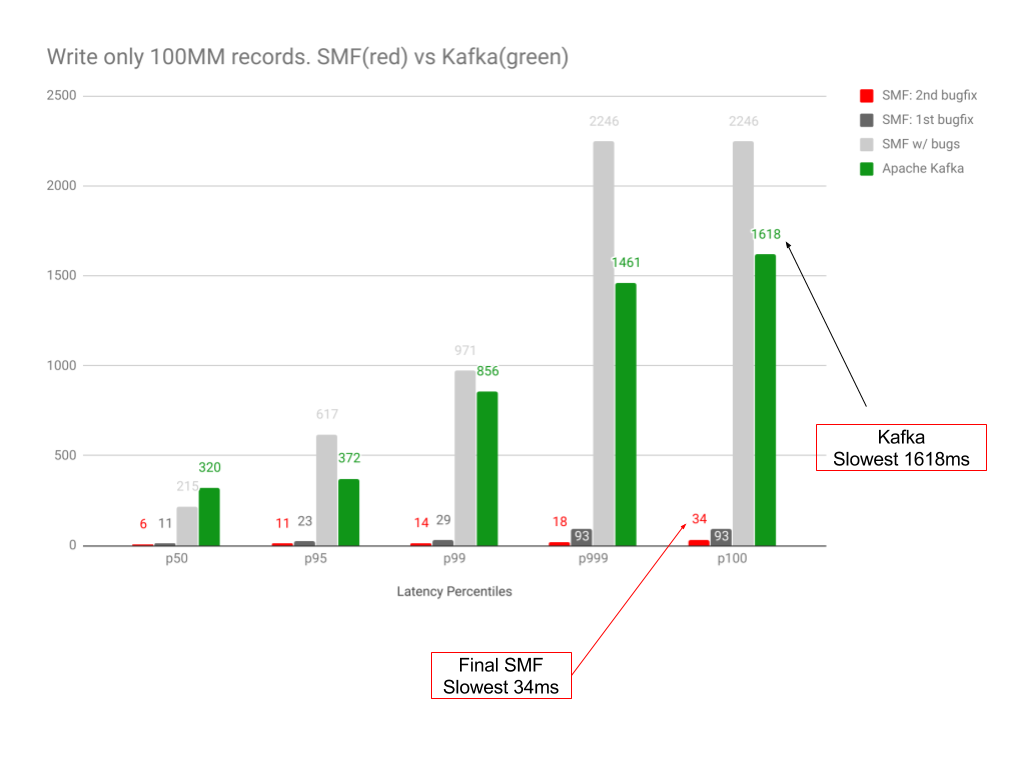
|
|
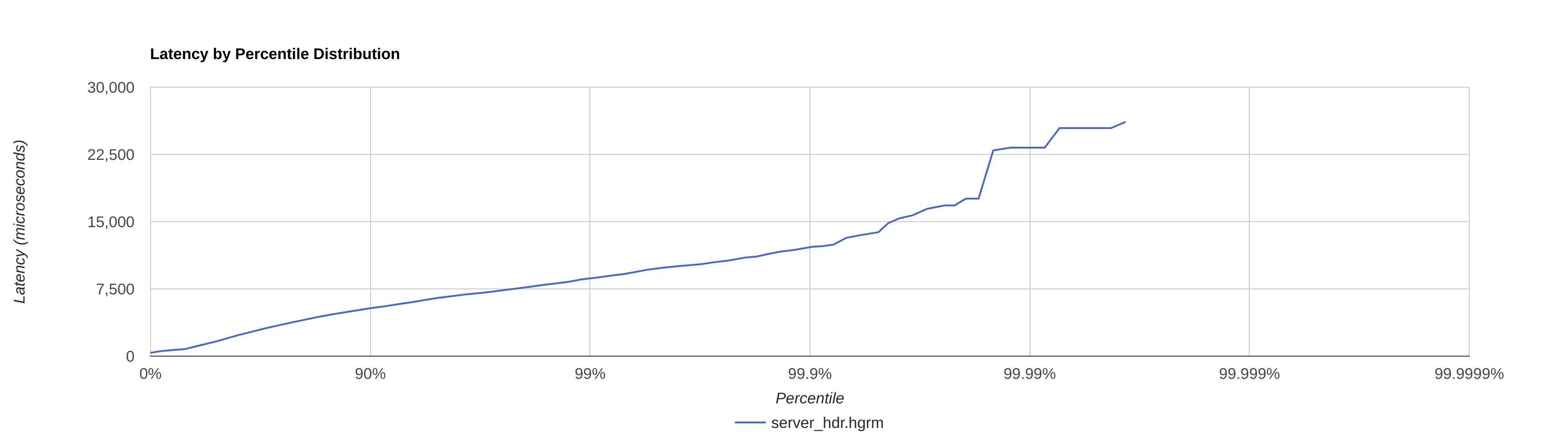
|
Performance, riddle me this!
At this point I was excited that we were back on track for having
possibly the fastest open source write ahead log … so I
decided to do one more pass through at perf stat -F 99 -d -p <pid>
… bad idea.
|
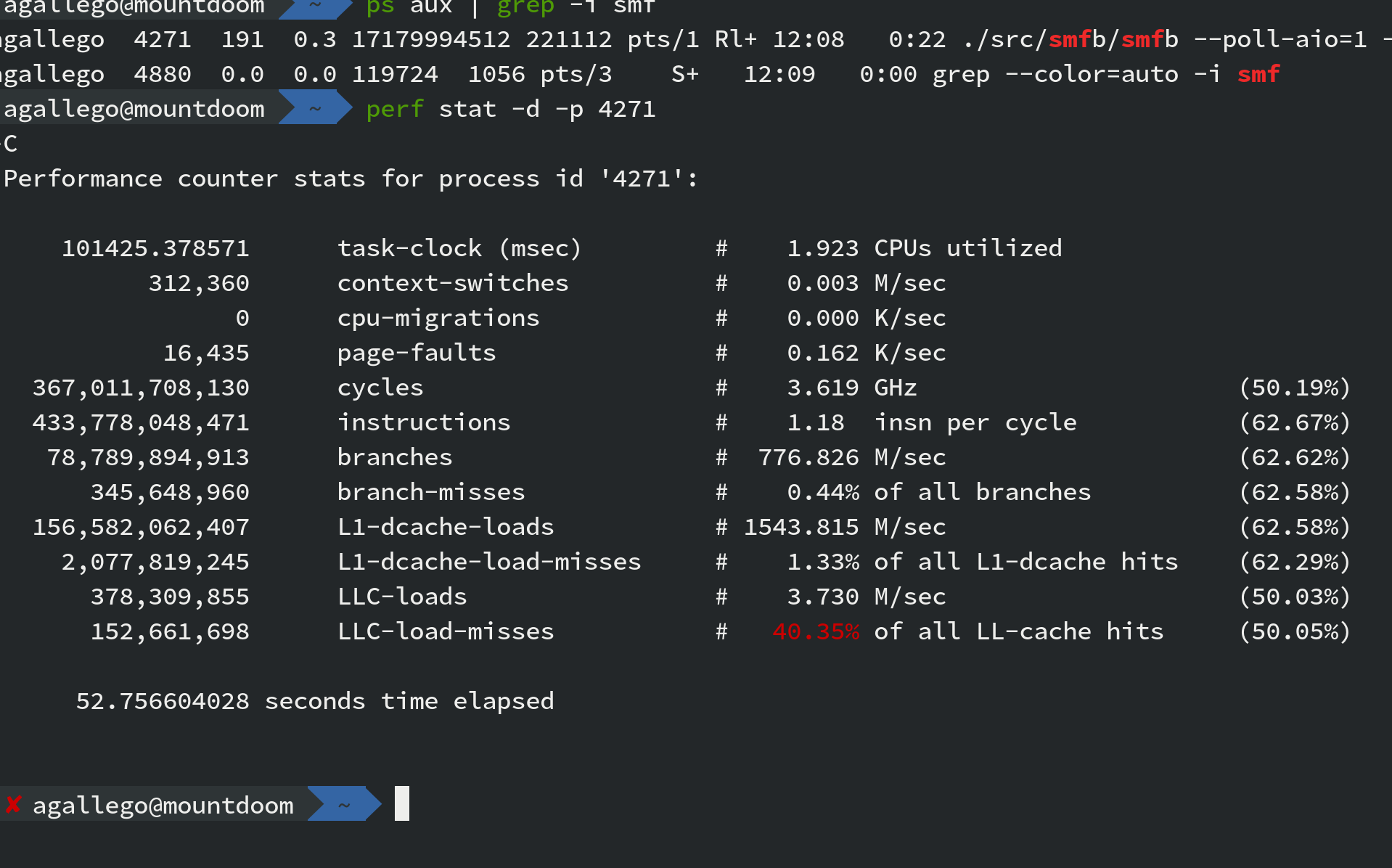
|
…………WHATTTTTT!!!!!! HULK SMASH KEYBOARD!!!!!
After all this work I have more Last-Level-Cache misses?!!? I was honestly going in circles at this point. I asked my friend @duarte_nunes to see what he thought and he recommented for me to take a look at toplev - a program from Andi Kleen to measure and make sense of CPU hardware counters.
Toplev next…
This is an area of ongoing effort, and I hope to write more about toplev and how I got another 10X performance improvement (fingers crossed). What prevented me from digging a bit futher is that my toplev profiles look difficult to understand.
Depending on the queue workload, the profiles change drastically from 0% Front End to 21% Front End bound workload.
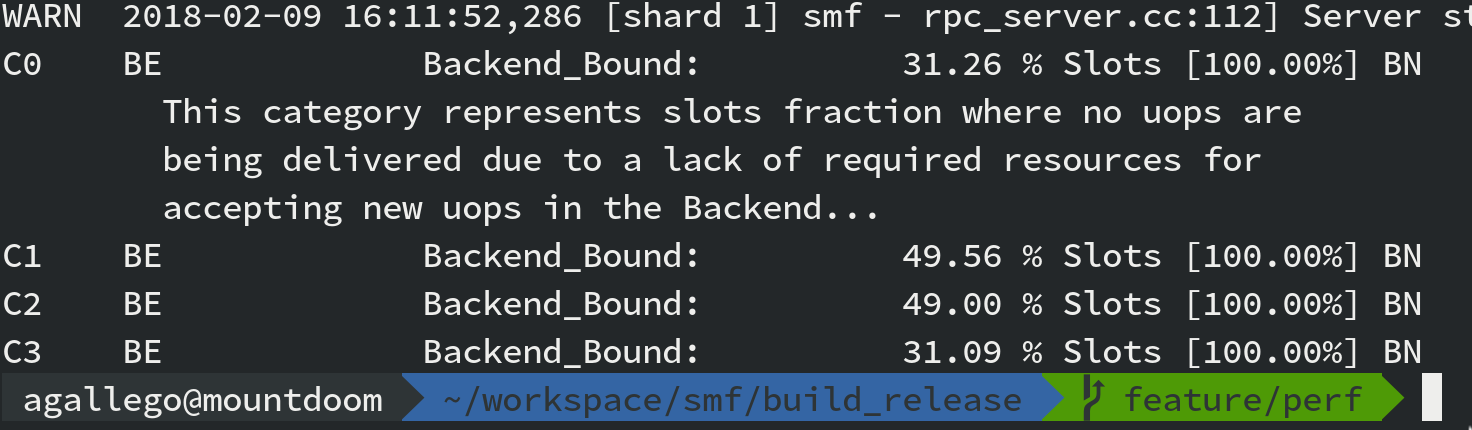 |
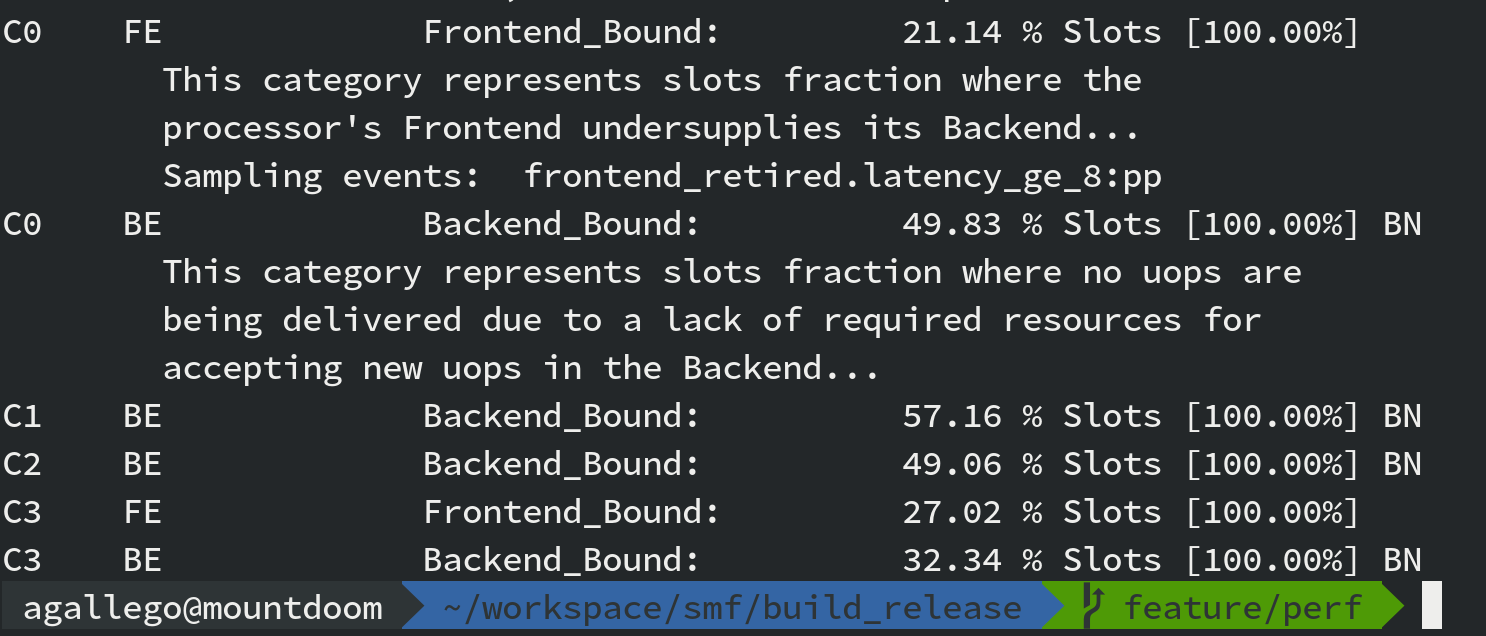
|
Before i dug deeper into the issues, I created a CPU FlameGraph to see if maybe there was something that I missed recording traces & probes… the results were suprisingly positive:

|
When I accidentally created this graph, I realized all along that the
reason for LLC-cache-misses came from the --poll-mode flag.
Without it, my perf stat -F 99 -d -p <pid> looked pretty good!
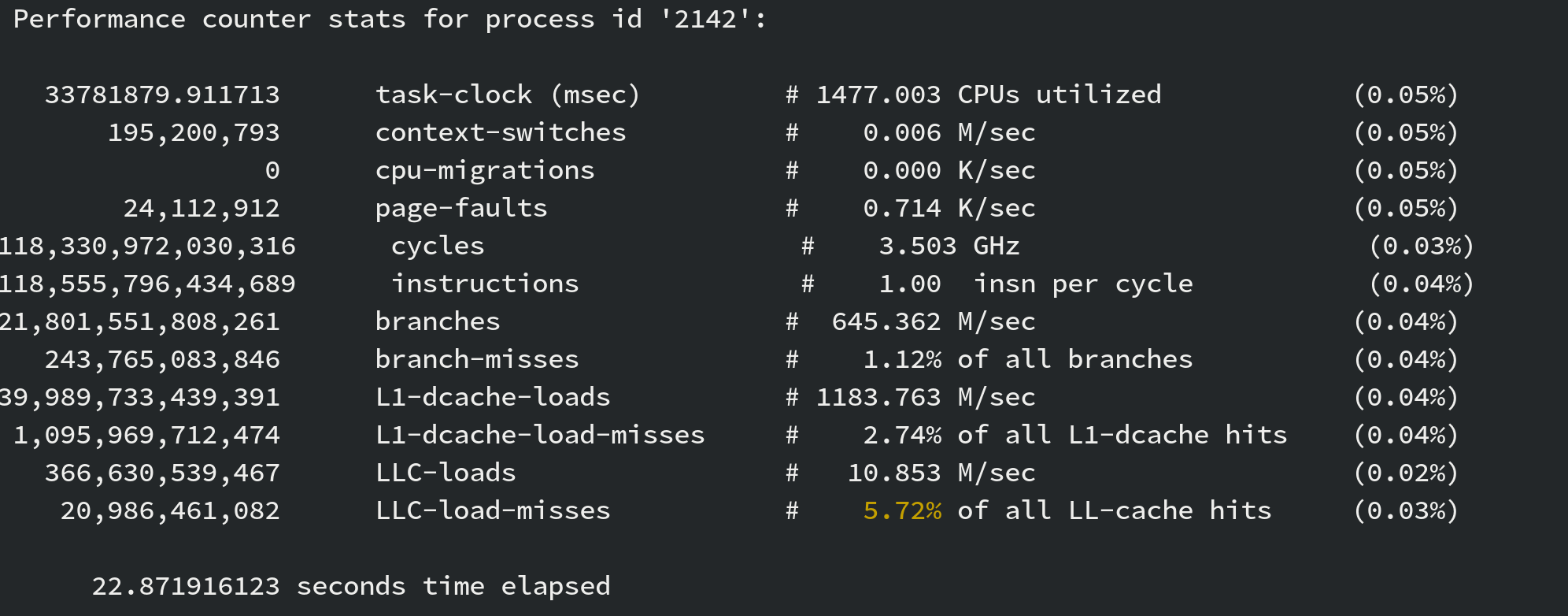
|
Low latency queueing might sounds like a silly goal for some, given that most BigData systems are used for offline flows. Dequeue, process, re-enqueue is the usual paradigm for most log brokers, where processing is in the 100s of milliseconds.
I do not think there exists a system today that can handle the load for the next generation of information flows in a cost efficient manner - Terabits/second. Low latency and high throughput will be a requirement to process drone logs, handle new security attacks, etc. I hope by then, either SMF or a system like it, designed to take advantage of every core, every storage device (of varying speeds) with a multitude of SLA’s can step up to the challenge.
Let me know if you found this useful on twitter @emaxerrno or on the comments.
Special thanks to my partner Sarah Rohrbach for reading earlier drafts of this post.